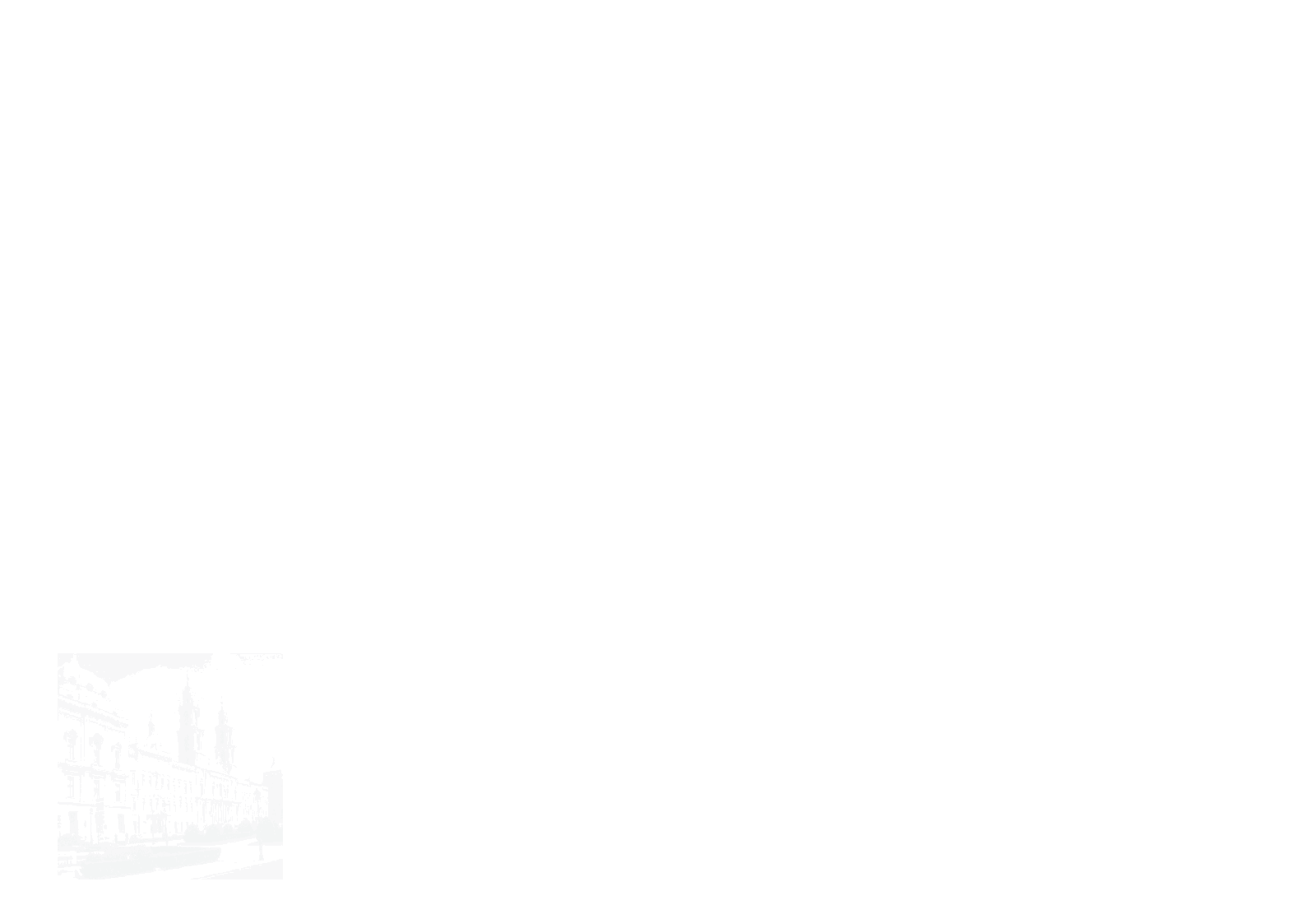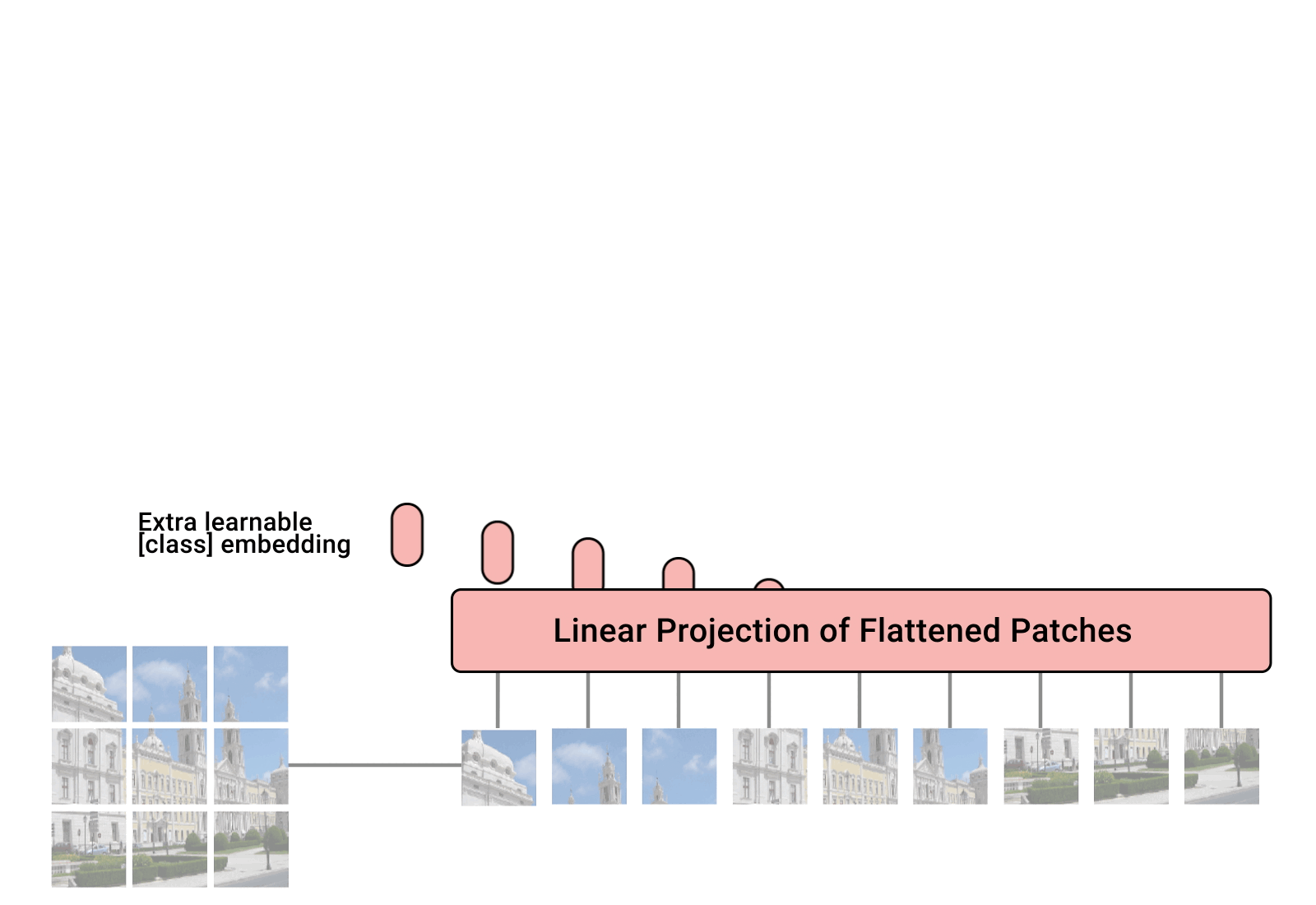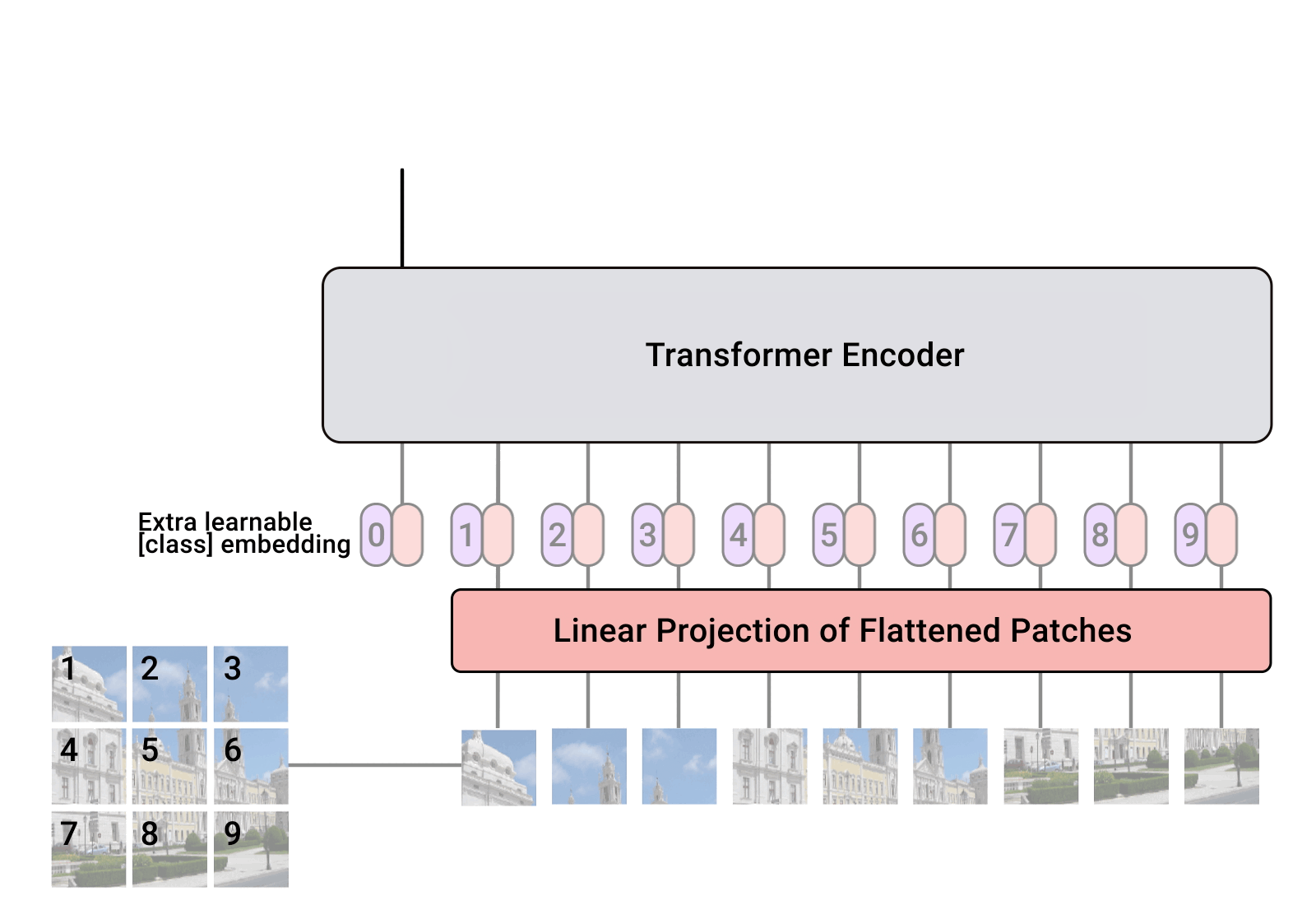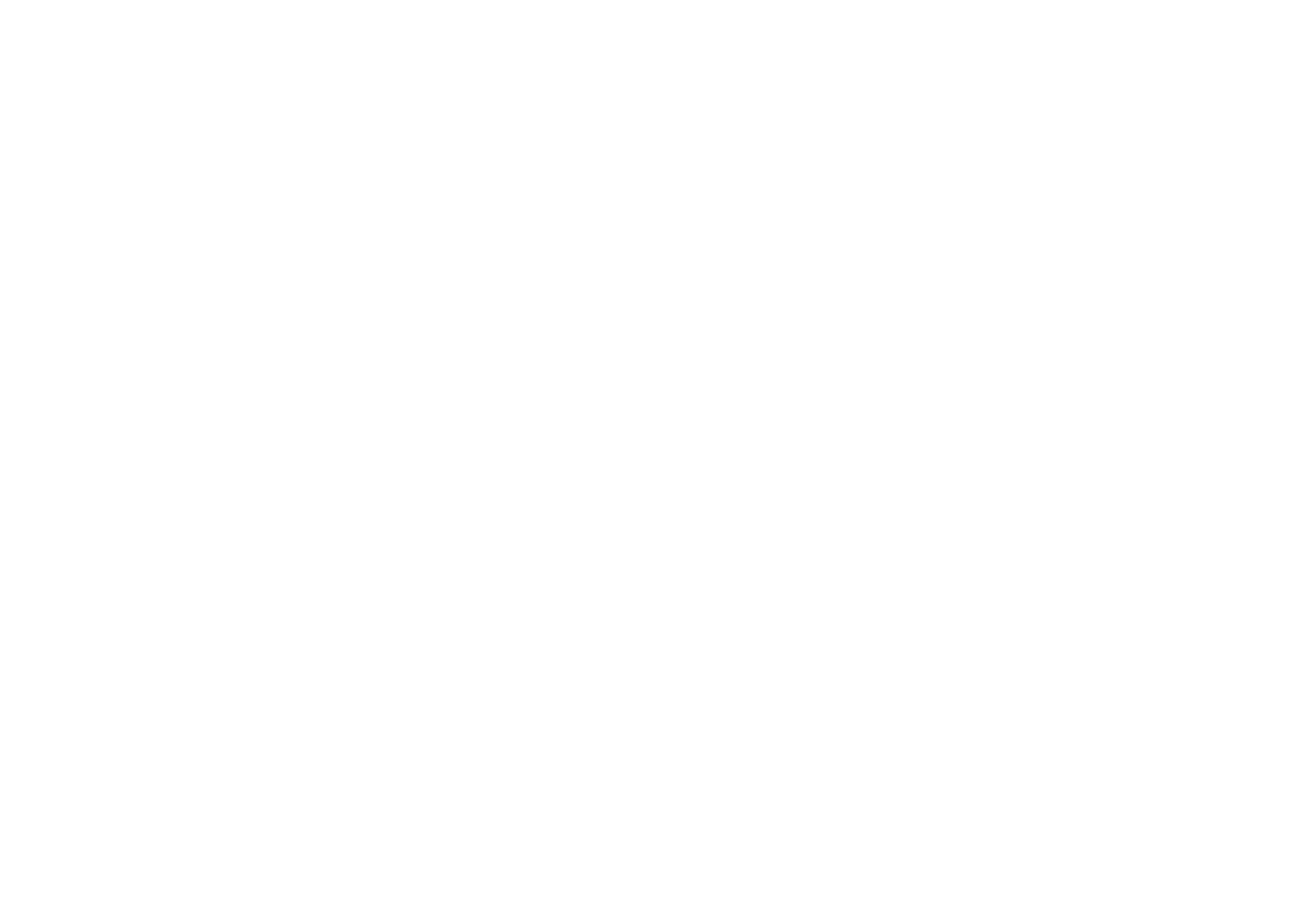
Originally developed for natural language processing, transformers are now being applied to computer vision tasks. The Vision Transformer (ViT), Swin Transformer, and Swin-Unet exemplify how transformer architectures can be utilized for object detection and image segmentation in computer vision.
ViT adapts the transformer model by dividing images into patches and processing them as sequences to capture long-range dependencies and global context more effectively than traditional CNNs.
Swin Transformer introduces a hierarchical architecture with shifted windows, computing self-attention within local windows and shifting them between layers to connect neighboring regions, which reduces computational complexity and handles images at various scales.
Swin-Unet integrates the Swin Transformer's shifted window approach into a U-Net-like architecture for image segmentation, enhancing precise localization and context understanding.
These models demonstrate the versatility and power of transformers in capturing both local and global features, leading to significant advancements in object detection and image segmentation compared to traditional methods.